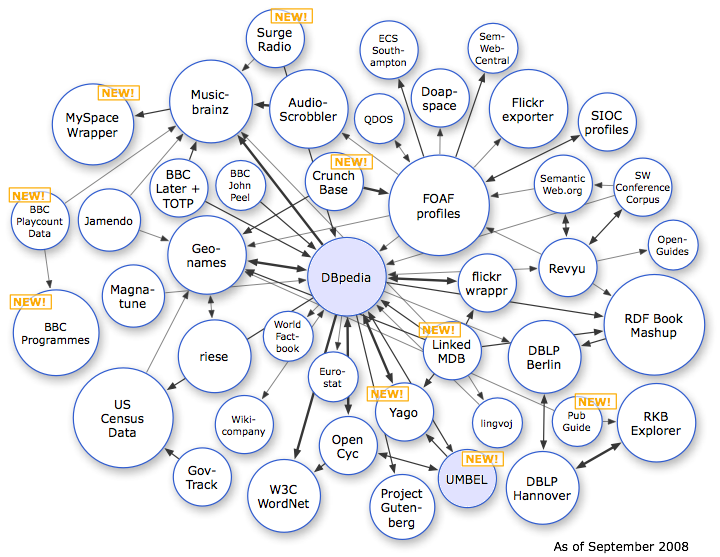
When I started learning Java around 8 years ago, I had a problem. Because I'd already known C and C++, it was very hard for me to get input from console using Java code. C and C++ need just a line to get input whereas for Java we'd required a lot. Now it's more easier using Scanner class :
Reading From Keyboard :
import java.util.Scanner;
public class ScannerDemo {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
//
// Read string input for username
//
System.out.print("Username: ");
String username = scanner.nextLine();
//
// Read string input for password
//
System.out.print("Password: ");
String password = scanner.nextLine();
//
// Read an integer input for another challenge
//
System.out.print("What is 2 + 2: ");
int result = scanner.nextInt();
if (username.equals("admin") && password.equals("secret") && result == 4) {
System.out.println("Welcome to Java Application");
} else {
System.out.println("Invalid username or password, access denied!");
}
}
}
Note: Code is taken from this
URL.
Reading From File:
import java.util.Scanner;
import java.io.*;
class HelpFile
{
public static void main(String[] args) throws IOException
{
Scanner scanner = new Scanner(new File("test.txt"));
while (scanner.hasNextLine())
System.out.println(scanner.nextLine());
}
}
Reading From Socket:
Scanner remote = new Scanner(socket.getInputStream());
PrintWriter out = new PrintWriter(socket.getOutputStream(), true);
//read line from keyboard
line = keyboard.nextLine();
//send line to remote node
out.println(line);
//wait for a line from remote node
line = remote.nextLine();
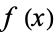 in a variable
in a variable 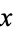 is denoted
is denoted 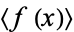 or
or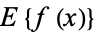 . For a single discrete variable, it is defined by
. For a single discrete variable, it is defined by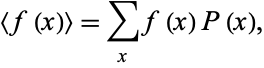 where
where 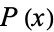 is the probability density function.
is the probability density function.